import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
import scipy.stats as stats
from sklearn.ensemble import RandomForestRegressor
import concurrent.futures
from datetime import datetime, timedelta
from sklearn.cluster import KMeans
import math
import scipy
from scipy import signal
from scipy.io import wavfile
from scipy.signal import find_peaks
from scipy.signal import sosfiltfilt, butter, ellip, cheby1, cheby2
# %matplotlib widget53 filtering 3
Now lets apply filtering to another dataset. Do you remember the phrase “I like to eat hummus”? When we applied dynamic time warping to that recording we messesed up with the samplerate to make the computation faster but the end result didn’t sound that clear. No that we know FFT and filtering, lets try to make it sound clearer by removing unwanted frequencies.
length = data1.shape[0] / samplerate
time = np.linspace(0., length, data1.shape[0])
fig, ax = plt.subplots()
ax.plot(time, data1)
ax.set_xlabel("Time [s]")
ax.set_ylabel("Amplitude")
plt.tight_layout()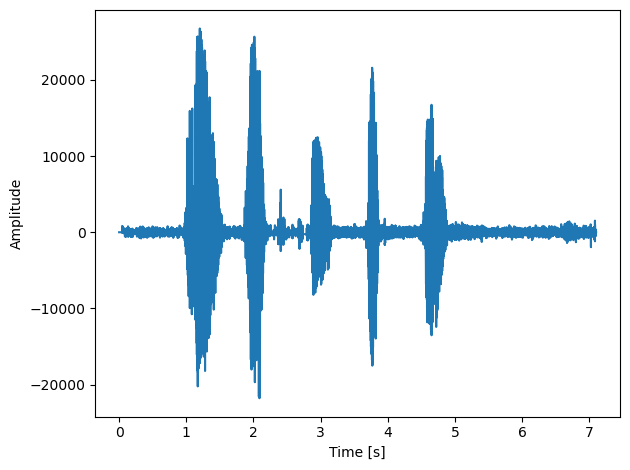
53.1 apply FFT
Keep only positive k values
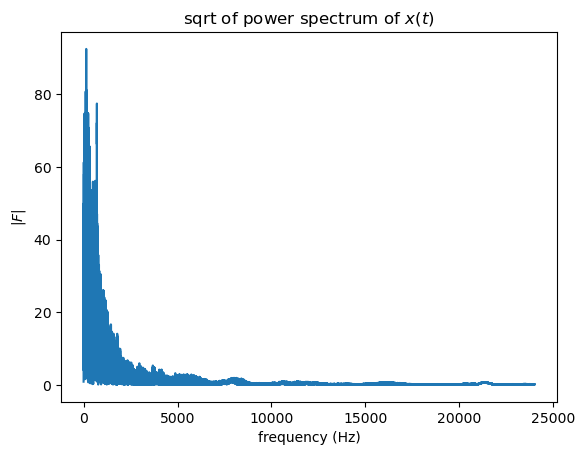
53.2 apply bandpass filter
In the recording we can hear that there are some undesired low and high frequencies. In general we will choose the band frequency to match the range of a male adult, which is approximately 300-5000Hz. 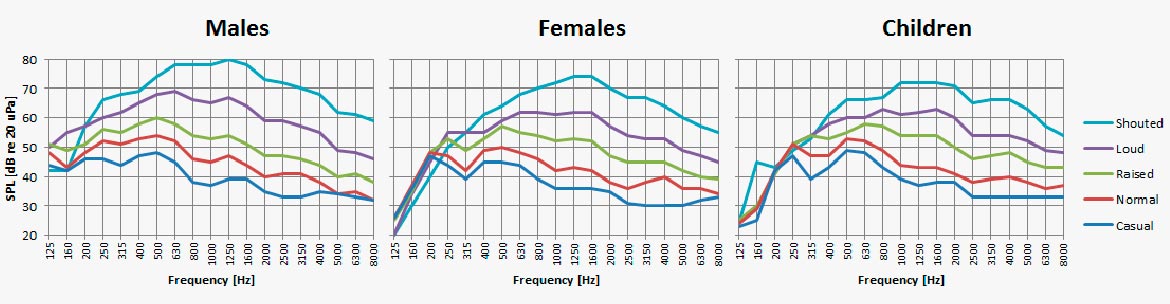
frequency_sample = samplerate
low = 300
high = 3000
sos = butter(4, #filter order = how steep is the slope
[low, high], # cutof value in units of the frequency sample
btype='band', #type of filter
output='sos', # "sos" stands for "Second-Order Sections."
fs=frequency_sample #frequency sample = how many samples per 1 unit.
)
# apply filter to the data:
y = sosfiltfilt(sos, x) + np.mean(x)
fig, ax = plt.subplots()
ax.plot(x, label='original')
ax.plot(y, label='filtered')
ax.legend()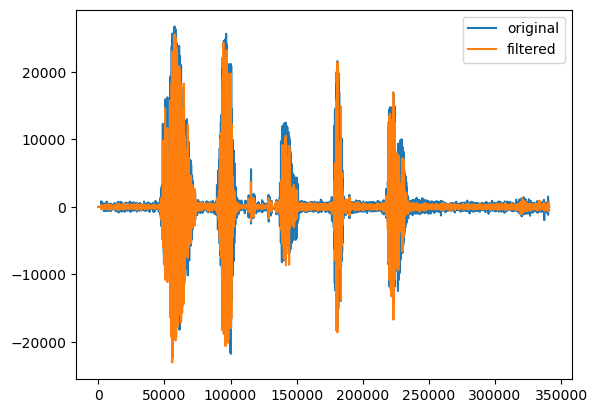
Lets compare the two:
original
filtered