“Past performance is not indicative of future results.”
Every investment firm has this disclaimer. Although it is generally very good practice not to heavily rely on any particularly successful hedgefund to take care of my business, I still find this sentence infuriating. If past performance is not indicative, then stop advertising last year’s returns! What’s more, how should I decide to whom entrust my investments (if at all) if a firm’s track record is “not indicative”?!
I will stipulate that the one question important to us is:
How can I study a system’s past behavior, so I can say something meaningful about its future?
There are many other interesting questions that I could have asked, but if you are with me that right now we will focus on the question above only, then there are many things that we should and should not do.
Data splitting, the name of this chapter, is a technical term, and we might think that it primarily deals with rules of thumb like splitting our dataset 70-30% between training and test sets. We can learn all that in other tutorials, not here. I will argue that data-splitting best practices are there to ensure the integrity of the question above.
55.2 NOT splitting the data
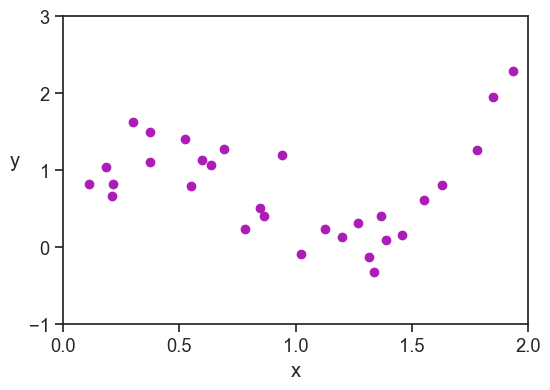
Let’s say that I conducted an experiment and collected 30 data points.
import libraries
import numpy as npimport matplotlib.pyplot as pltimport seaborn as snssns.set_theme(style="ticks", font_scale=1.2)from mpl_toolkits.mplot3d import Axes3D # noqa: F401from numpy.polynomial import Chebyshevimport statsmodels.api as smfrom sklearn.metrics import r2_score, mean_squared_errorblue ="xkcd:cerulean"gold ="xkcd:gold"pink ="xkcd:hot pink"green ="xkcd:forest"purple ="xkcd:barney"
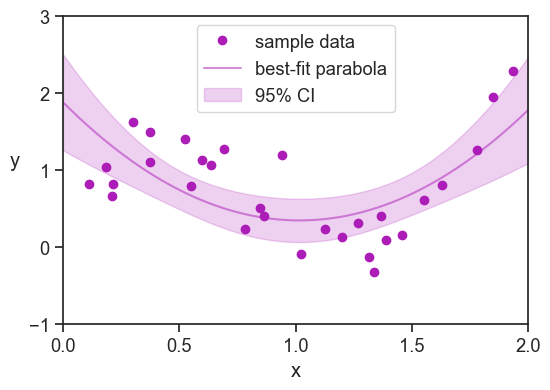
Best fit parabola: y = 1.5x^2 -3.0x + 1.9
Adjusted R^2: 0.36
RMSE: 0.51
p-value for positive x^2 coefficient: 0.0001
Here are a few things I could say about my findings:
The model explains 36% of the variance in the sample data.
The model’s performance, as measured by the root mean squared error against the sample data, is 0.51.
The sample data is best explained by a convex parabola (positive coefficient for the x^2 term), and the p-value for this coefficient is 0.0001 (against the null hypothesis of a zero coefficient).
All of this is fine, and I made sure to say “sample data” in all of the statements above. If all I’m interested is in describing the past, then all is good.
I might be tempted to say something more general, like:
The model captures 36% of the variance in this system.
We can predict the system’s behavior with an expected RMSE of 0.51.
We demonstrate that variabley has a convex relationship with variablex.
This is where we are in trouble. We have no reason to believe that the model’s performance on the sample data will be similar to its performance on future data from the same system. More generally, we have no reason to believe that the relationship between y and x in the sample data will be similar to the relationship between y and x in future data from the same system. It could be so, we just don’t know it.
And why not? Because we optimized the model to fit the sample data, and we never tested the model on data it hasn’t seen before. This simple fact prevents us from generalizing our findings to the system as a whole, and to future data from the system.
The conclusion here is that if we want to say something meaningful about the system in general, or about its future, then we need to put aside some of the data.
55.3 performance on unseen data
In general terms, we expect that the a model’s performance on unseen data will be worse than its performance on the data it was trained on. The reason should be obvious to us from now on: we optimized the model to fit the training data. Sure, it could be that by chance the performance on the unseen data is better than on the training data, but we have no reason to expect it.
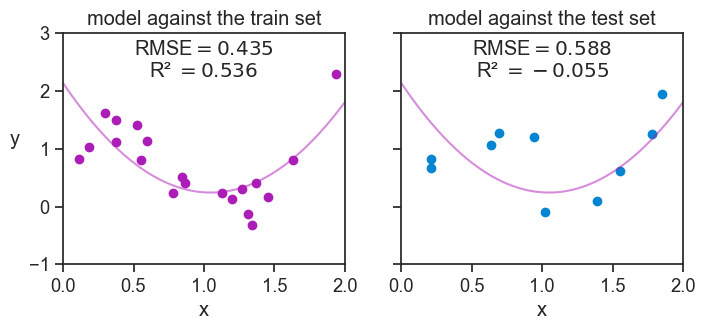
As an illustration, let’s say that we split our sample data of 30 points into a training set of 20 and a test set of 10. We fit the same degree 2 polynomial to the training data, and evaluate its performance on the test data.
As expected, the model’s performance on the test data, as measured by the RMSE and R-squared, is worse than its performance on the training data: the RMSE went up, and the R-squared went down. By chance, we had the “luck” of getting a negative R-squared on the test data! How is that possible?! In very few words, this means that the model is worse that useless. The model does so badly on the test data, that we would have been better off just predicting the mean of the test data for all test points, instead of using the model’s predictions. More on this point on the chapter on R-squared.
55.4 target leakage
This is when features contain information that would not be available at prediction time — e.g., including the answer or something correlated with the answer into the model. The result is overly optimistic performance that will not repeat in new data.
You can show a simple synthetic example where a “feature” directly encodes the target (say, with added noise) and then the evaluation looks good but fails on truly unseen data.
55.5 train–test contamination
This is when the test set ends up influencing the model, often through improper preprocessing. Common examples include:
scaling using global mean & std instead of training mean & std
feature selection done before splitting
shuffling time series data and randomly splitting despite temporal order
All of these are examples where information from the test set leaks into training.
A simple demonstration can be:
Fit a model with normalization applied to the whole dataset, then compare its test performance to the same model with normalization done properly only on training data.
That produces two curves where the first looks unrealistically good.
Show the code
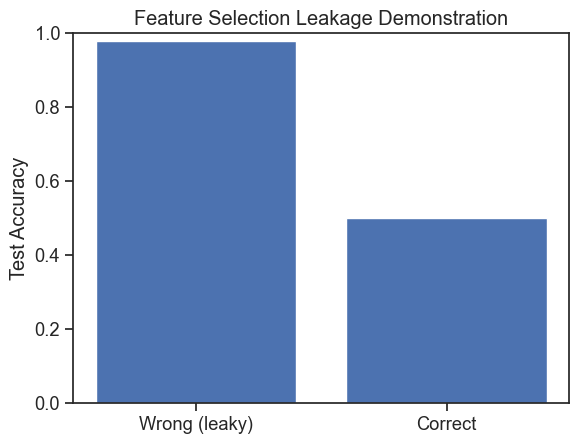
# ------------------------------------------------------------# feature selection leakage demonstration (gene example)# ------------------------------------------------------------import numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_scorefrom sklearn.model_selection import train_test_split# -------------------------# 1. generate synthetic data# -------------------------np.random.seed(0)n_samples =120# number of patientsn_features =20000# number of genes (all noise!)# gene expression: pure noiseX = np.random.normal(size=(n_samples, n_features))# disease label: random (no relationship to genes)y = np.random.randint(0, 2, size=n_samples)# -------------------------# 2. WRONG approach: feature selection before splitting# -------------------------# compute correlation between each gene and the labelcorrelations = np.array([ np.corrcoef(X[:, j], y)[0, 1] for j inrange(n_features)])# select top 50 most correlated genes (using ALL data)top_k =50top_features_wrong = np.argsort(np.abs(correlations))[-top_k:]X_selected_wrong = X[:, top_features_wrong]# now split AFTER feature selection (this is the mistake)X_train_w, X_test_w, y_train_w, y_test_w = train_test_split( X_selected_wrong, y, test_size=0.4, random_state=42)model_wrong = LogisticRegression(max_iter=1000)model_wrong.fit(X_train_w, y_train_w)y_pred_w = model_wrong.predict(X_test_w)acc_wrong = accuracy_score(y_test_w, y_pred_w)print("WRONG pipeline (feature selection before split)")print(f"Test accuracy: {acc_wrong:.3f}")print()# -------------------------# 3. CORRECT approach: split first, then select features# -------------------------# split raw data firstX_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.4, random_state=42)# compute correlations ONLY on training datacorrelations_train = np.array([ np.corrcoef(X_train[:, j], y_train)[0, 1] for j inrange(n_features)])top_features_correct = np.argsort(np.abs(correlations_train))[-top_k:]X_train_c = X_train[:, top_features_correct]X_test_c = X_test[:, top_features_correct]model_correct = LogisticRegression(max_iter=1000)model_correct.fit(X_train_c, y_train)y_pred_c = model_correct.predict(X_test_c)acc_correct = accuracy_score(y_test, y_pred_c)print("CORRECT pipeline (split before feature selection)")print(f"Test accuracy: {acc_correct:.3f}")print()# -------------------------# 4. visualize comparison# -------------------------plt.figure()plt.bar(["Wrong (leaky)", "Correct"], [acc_wrong, acc_correct])plt.ylabel("Test Accuracy")plt.title("Feature Selection Leakage Demonstration")plt.ylim(0, 1)plt.show()
WRONG pipeline (feature selection before split)
Test accuracy: 0.979
CORRECT pipeline (split before feature selection)
Test accuracy: 0.500
55.6 time / sequence dependencies
If your data has a temporal structure, a random split can “expose” future points during training. You can illustrate this with synthetic time series — or even simpler: show that if you shuffle a temporal dataset, the model appears to perform well, but if you respect time order, performance drops.
This is a perfect example of contamination through mishandling the structure of the data
55.7 group leakage
Another subtle case is when units in the data are correlated — e.g., multiple observations from the same subject or cluster — but you split randomly instead of by group. The model ends up trained on data “too similar” to test.
You can illustrate this with a toy example where each group has its own bias — random splits mistakenly allow the model to learn that bias.