In the previous section, we solved a simple 2x2 grid where the mouse only had to worry about whether a fox was present or absent. While that was a great starting point, the real world is rarely that discrete. To move toward a more realistic model, we must consider the world as a continuous space.
6.1 moving to continuous states
Imagine that the mouse is no longer just asking “is there a fox?” but is instead trying to estimate the distance of the fox from the burrow.
External state x^\star: The physical, objective distance of the fox (e.g., 100 meters).
Hidden state x: The latent state in the mouse’s model, corresponding here to fox distance. The mouse does not observe x directly; it must infer a belief distribution over x from sensory data.
Sensory outcome y: The continuous intensity of the fox’s scent reaching the mouse’s nose.
In this scenario, the mouse’s generative model is no longer a simple table. It is a continuous joint probability density function (PDF), p(x, y). This function maps how likely a specific smell intensity y is, given a specific distance x, weighted by how likely the mouse thinks that distance was in the first place (the prior).
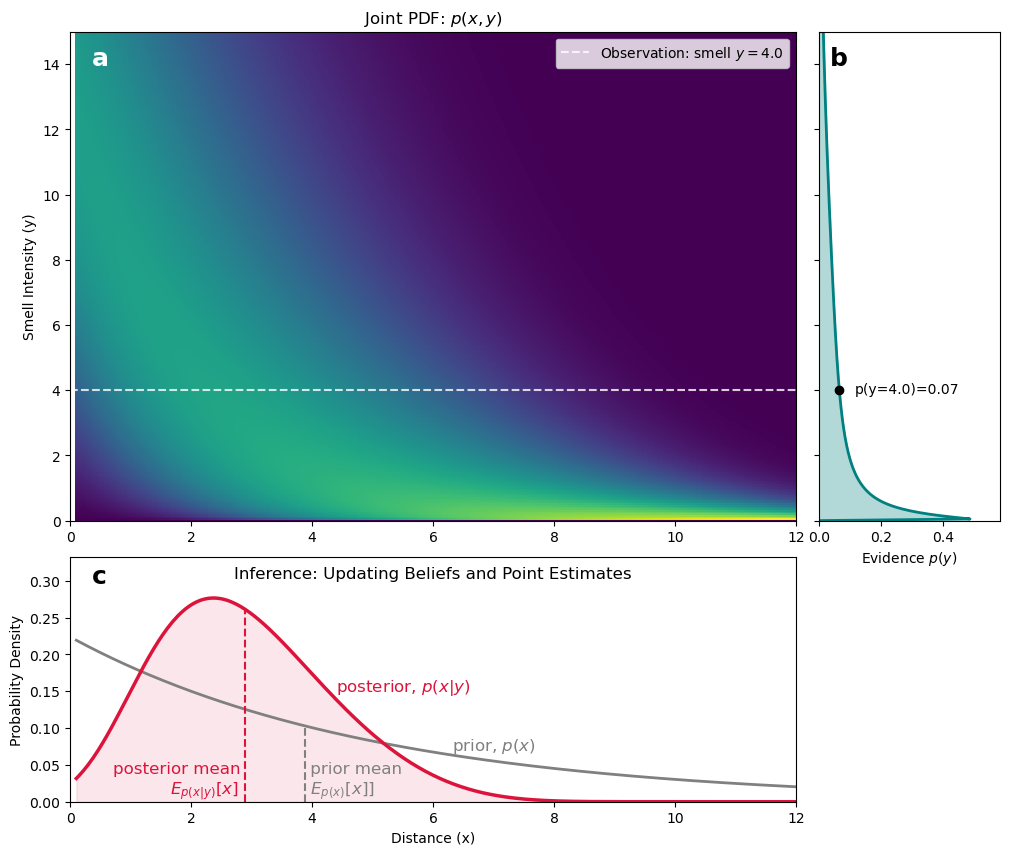
Assume that the mouse started with a prior probability density for the fox’s distance as shown by the gray curve in panel c. The expected value (center of mass) of this prior is 3.87 (in standard mouse units). The mouse then receives a sensory observation of y=4.0. The mouse uses its internal generative model to figure out what this means. The generative model is the joint PDF shown in panel a, which encodes the likelihood of observing different scent intensities at different distances, multiplied by the prior belief about those distances. By slicing through this joint PDF at the observed scent intensity of y=4.0 (gray dashed line), the mouse can find the numerator of Bayes’ rule, p(x, y=4.0). To get the posterior, the mouse needs to normalize this slice by the evidence p(y=4.0). The full curve for the evidence p(y) is shown in panel b, and it can be calculated by integrating the joint PDF over all distances x, that is, integrating over the horizontal axis of panel a. This integral gives us the marginal probability of observing that scent intensity, regardless of the distance. The value of the evidence at y=4.0 is shown as a black dot in panel b, and it equals 0.07. This value is the denominator in Bayes’ rule. Strictly speaking, this is not the probability of observing exactly y=4.0, but the probability density around that sensory value. Finally, the mouse divides the slice of the joint PDF at y=4.0 by this evidence value to get the posterior PDF over distances given the observed scent intensity. This is the red curve in panel c. The center of mass of the posterior is 2.89, which is closer than the prior mean of 3.87, indicating that after sniffing a smell intensity of 4.0, the mouse now thinks that the fox is likely closer than it previously thought.
Easy, right?
6.2 the problem of degeneracy
At first glance, this seems like a “simple enough” upgrade to the example from the previous section. If the mouse gets a smell intensity of y=4, it can just look at the corresponding “slice” of the joint PDF and find the most likely distance. In our Python “cartoon,” this is a trivial numerical task.
However, real-world sensory data is degenerate. This means that a single sensory input (a faint smell) could be caused by many different configurations of the world.
The fox is far away on a breezy day.
The fox is very close, but the wind is blowing the scent away from the burrow.
The fox is medium-distance, but the mouse has a stuffed nose (sensor noise).
If the mouse only models “distance”, its likelihood mapping p(y|x) must be extremely “blurry” to account for all that wind-related uncertainty. A model that collapses all this uncertainty into distance alone becomes very broad: the same smell intensity is compatible with many possible distances.
6.3 the problem of generalization
There is an even deeper problem. In the 2×2 example, it was reasonable to imagine that the mouse had learned the full likelihood matrix from experience. But in a continuous, high-dimensional world, this is impossible. The mouse has never experienced every possible combination of distance, wind direction, wind speed, humidity, vegetation, and fox behavior. Therefore, it cannot simply store a giant likelihood table.
To survive, the mouse needs a generative model with structure. It must assume that smells behave in lawful ways: they tend to weaken with distance, drift with wind, and become noisier under turbulent conditions. These assumptions allow the mouse to generalize beyond direct experience. In other words, the generative model is not just memory; it is a compressed, structured model of how hidden causes generate sensory data.
But even with structure, inference remains difficult. Once the model contains many hidden causes, the mouse must infer a whole configuration of the world, not just one variable. This brings us to the curse of dimensionality.
6.4 the curse of dimensionality
To gain precision, the mouse must expand its hidden state x into a high-dimensional vector. It must model not just distance, but also wind velocity, wind direction, and turbulence, not to speak of the fox’s behavior and the possibility that there are multiple foxes. These are “nuisance variables”—the mouse doesn’t care about the wind for its own sake, but it must infer the state of the wind to “de-noise” the smell of the fox.
As we add these necessary dimensions (distance, angle, velocity, wind speed, turbulence, humidity, etc.), our “easy” Bayesian solution falls apart:
The Integral Problem: To find the evidencep(y), the mouse must now integrate over all these dimensions simultaneously.
Computational Collapse: If we used the same 300-point grid from our Python script for 10 dimensions, we would need 300^{10} calculations. That is roughly 5 \times 10^{24} operations—far more than any biological brain can compute in the split second needed to escape a predator. If we tried to solve the posterior by explicitly evaluating the joint density on a grid, as we did in the simple Python example, the computation would explode.
6.5 the need for a shortcut
This is the statistical inverse problem in its true form. The sensory data are generated by hidden causes, but many different hidden causes can produce the same sensory outcome. Exact Bayesian inference tells us what the ideal posterior should be, but in high-dimensional environments computing it directly becomes impossible. Variational inference provides a shortcut: instead of calculating the exact posterior, the system maintains an approximate belief distribution q(x) and adjusts it to better explain the sensory data. This move—from exact inference to approximate inference—is the mathematical doorway into active inference.